Я тут проект под ключ реализовал
Для кого заключительная неделя перед релизом, а для меня первый день отпуска. Отоспавшись на выходных, решил подвести итоги своей работы за полдгода.
С декабря месяца я взялся поднимать функциональность аналитики и отчетности в АСМ(это продукт, разработкой которого я занимаюсь). План был прост:
1) Собрать команду
2) Разобраться в устройстве корпоративных хранилищ данных, ведь аналитика и отчетность строится на каких-то данных, а данные еще нужно сложить и подготовить для отображения(привет data engineering).
3) Разобраться в моделирование бизнес-процессов для подготовки аналитических данных.
4) Сделать хранилище и смоделировать один бизнес процесс для обкатки выбранных подходов и инструментов.
5) Сделать отображение данных в графиках и таблицах.
И тут в целом можно было вспомнить, что я так-то бекенд разработчик, чем я тут вообще занимаюсь. Но вспоминать было некогда — работы вагон и еще три состава:
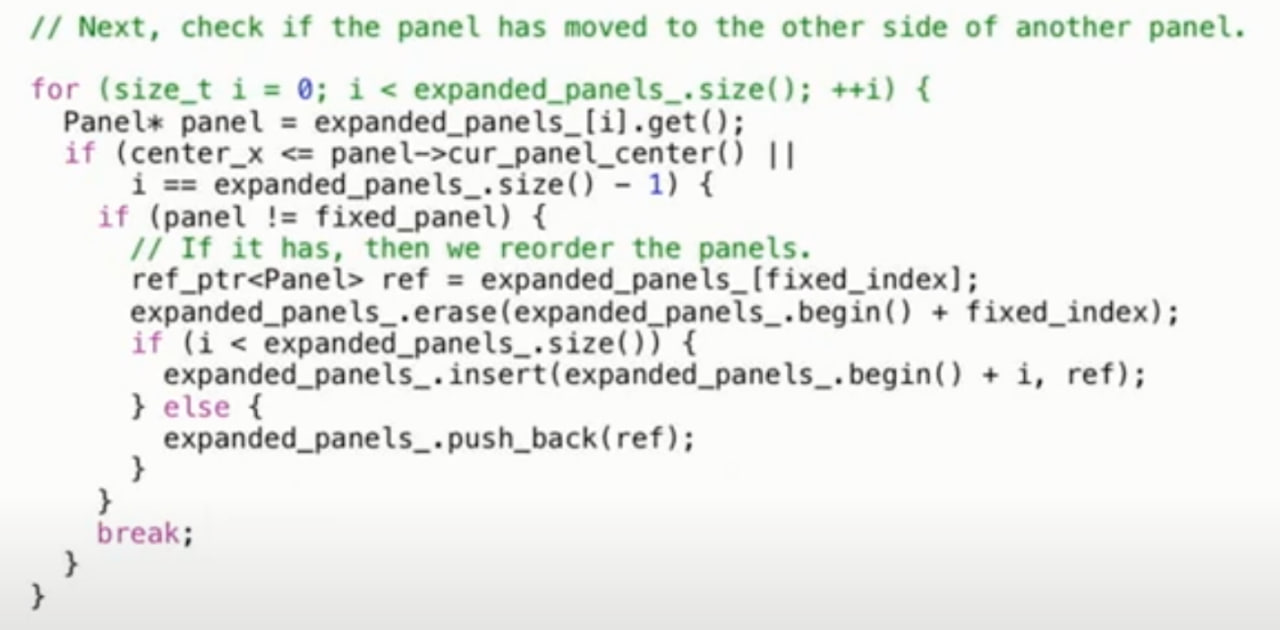
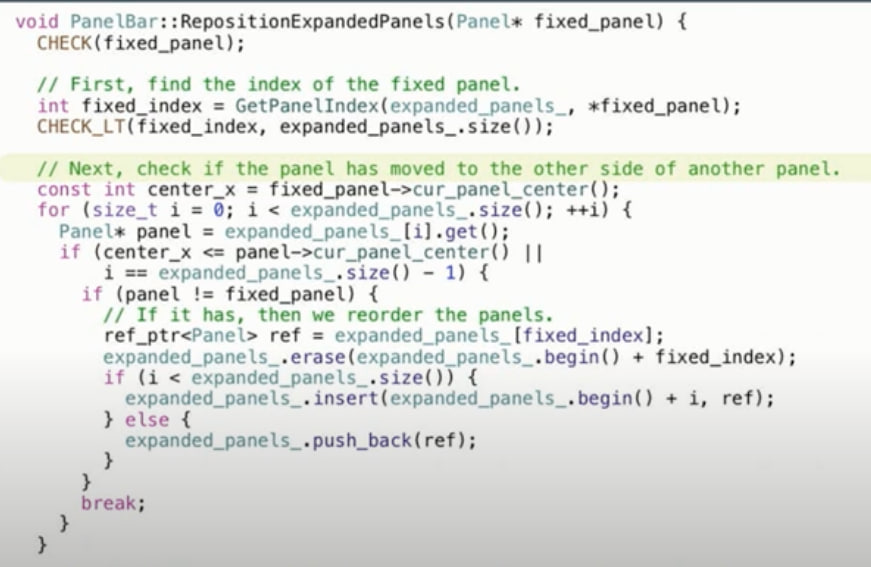
— Вместо одного бизнес процесса моделировать пришлось 5. Два месяца я засыпал и просыпался я в обнимку с томиком Кимбалла.
— Параллельно происходил ресерч и обоснование выбранных технологий для построения ETL-процессов и отображения данных, ресурсов на разработку собственных решений за отведенное время нет.
— Команда собрана. Нас пятеро друзей Оушена.
— Мы соответствуем РБПО, поэтому выбранные инструменты затянуты к себе и взяты на поддержку.
— Были подняты стенды для дев и целевой среды, так на свет родились deb-пакеты для Airflow и Superset, несуществовавшие в природе до этого. CI часть этого всего — это почти еще один продукт :)
— Разработаны ETL-процессы. Полностью. С нуля.
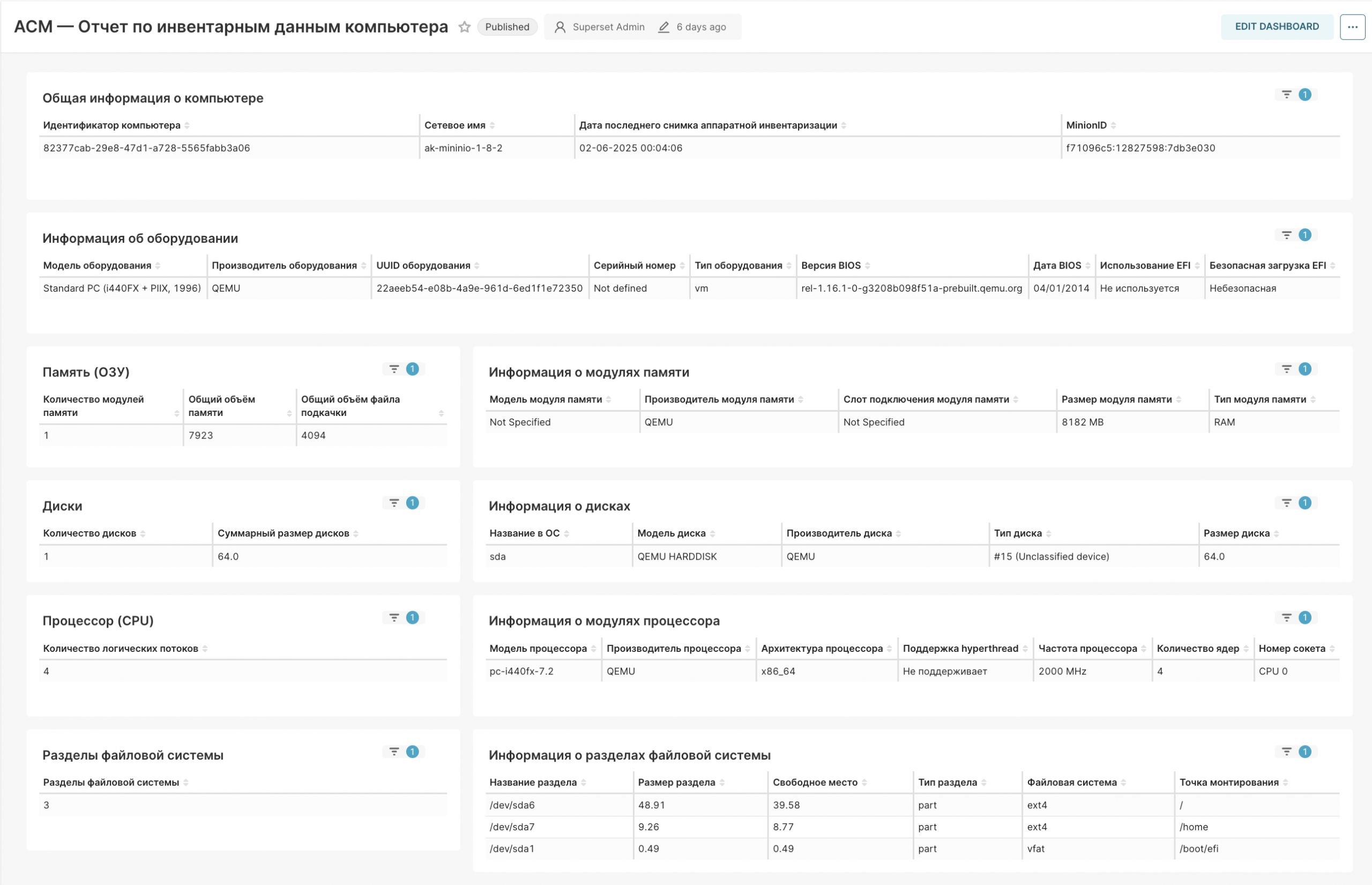
— Разработаны предустановленные отображения для данных. 6 страниц с кучей данных и переходами между друг другом, связанные общими фильтрами.
— Мы разворачиваемся у клиента с минимальными махинациями в админках используемых инструментов — так в dag-скриптах появились env’ы с подключением к БД и автоматический импорт дашбордов.
— Документация. Мы еще даже рассказываем, как при желании сделать собственные страницы с отчетами и как у нас там данные лежат.
Список можно продолжать и дальше, привел ключевые пункты. На самом деле делать пришлось больше запланировано, в конце апреля я сидел и думал, успеем ли мы все сделать. Сделали большую часть, прям блин большую.
Выпускаемся и смотрим, что делаем дальше. Жду обратную связь от пользователей.
Сделано столько работы, а это будто лишь начало пути.