Фото специально размыто, коммерческая тайна и все такое :)
Последний раз писал апишку почти год назад. Сейчас временно моя команда раскидалась на помощь другим, я пошел помогать в старую команду и сел запиливать базовые CRUD операции, тыкать в аналитиков палкой, требуя спецификации к входным и выходным схемам, в темпе вальса мокать апишку, чтобы фронты могли потестить свою верстку и все такое. Типичное крудошлепство, почти отдых, за исключением того, что сервис совсем новый, только в CI закинута болванка сервиса, чтобы можно было деплоится, и все.
Наши сервисы имеют слоистую архитектуру с кучей другой паттернов: адаптеры, репозитории для запросов в хранилище, команды и запросы(привет CQRS), unit of work для обеспечения транзакционности действий в системе, агрегаты, сервисы, билдеры на сервисы и билдеры на модели, все еще на интерфейсах, чтобы тестировать удобно было... Чтобы реализовать ручку, нужно реализовать 5-6 интерфейсов и реализаций. Ситуация, как в тех бородатых анекдотах про реализацию чего-угодно в Java: сначала напишите фабрику, а если фабрика уже есть — напишите абстрактную фабрику. Пришлось вспоминать, как вообще все эти сущности между собой должны дружить.
Понятно, что вернувшись через год к типу задач, реализация которых подразумевает кучу всего, нужно будет переключить мозги, но по моему мнению, если ты возвращаешься к своему проекту и вообще не понимаешь, что тут и как работает — это либо ты сильно все упростил, либо сильно перемудрил. Причем с первым разобраться сильно проще, чем со вторым, на мой взгляд.
Отсюда два вывода:
1) Настраивайте себе шаблонизаторы, когда у вас устоявшиеся подходы.
2) Если ваш сервис предполагает, что про его разработку забудут на полгода-год(на моей памяти есть такой сервис для получения курса валют), есть смысл писать его проще — в плоских структурах и куче if-ов быстрее разобраться(да-да, рубрика «Вредные советы»). Опять же если не написана совсем жесть, тогда земля пухом 🔫.
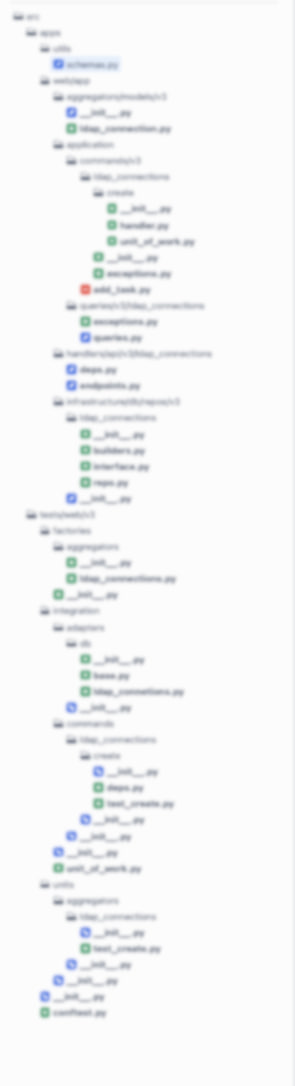
💻 Всем доброй ночи, а я пошел запиливать себе шаблоны наконец-то, ибо те 30 файликов на скрине ПРа меня утомили. Это кстати реализация Create операции, с тестами...